Ola para você que se esbarrou com esse post. O assunto de hoje é sobre Decision Trees e mostrarei uma ideia bem interessante, que é o uso de Decision Trees para regressões.
Porem antes vamos definir o que é uma regressão no nosso contesto. Existem várias explicações e definições para o assunto de uma olhada no wikipedia caso queira se aprofundar.
Mas para nosso contesto definiremos regressão como o ato de classificar um valor continuo com base em uma instância ou vetor.
Resolva exercícios e atividades acadêmicas
Para quem já entende de Álgebra linear seria como uma transformada de para.
Espero que tenha ficado minimamente claro a tarefa de hoje, caso não, continue lendo o post que as coisas darão uma clareada.
Encontre o professor particular perfeito

Em outras palavras: No contexto de Machine Learning Regressão é o nome dado ao ato de se associar um valor continuo a uma instância.
A principal diferença entre classificação e regressão é que enquanto na primeira as classes pertencem a um conjunto finito na segundo temos classe pertencendo a um conjunto infinito, geralmente dentro de um intervalo, mesmo assim vareado demais para ser contado.
Isso definido vamos ao que interessa. Primeiramente precisamos de um Dataset para trabalharmos. Hoje eu trouxe um Dataset fictício que mostra variação no preço de uma ação semanalmente de acordo com 3 índices: variação no IPCA, variação no índice Ibovéspa e variação do Dólar.
Tutoria com Inteligência Artificial
Tecnologia do ChatGPT. Use texto, áudio, fotos, imagens e arquivos.
Queremos saber a variação no preço de uma ação em função da variação desses índices.
O conjunto todo tem 25 instâncias separei 20 para treino e o resto deixarei para teste.

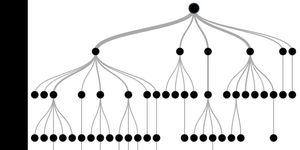
Uma vez tendo nossa tabela em mãos a missão agora é construir uma árvore que consiga nos dizer com maior precisão possível qual será a variação no preço da ação com base na variação desses três Índices.
Para quem já sabe o que é uma Decision tree a ideia é muito simples vamos substituir o Score de referência que geralmente é para classificação como Entropia ou Gini impurity por um que consiga lidar melhor com variáveis contínuas como Média e Variância por exemplo.
A maneira que escolhi para construir a árvore não a ideal ainda mais para conjuntos de dados pequenos. Mas a missão aqui é te mostrar de maneira intuitiva como o modelo se desenvolve por isso usaremos esse método pela simplicidade.
Caso se interesse em aplicar o conceito te aconselho a não fazer exatamente dessa forma na prática pois existem vários detalhes que devem ser analisados como instâncias ruídos a quantidade ideal de dados o tipo de distribuição probabilística do conjunto e mais um bocado de coisas.
Treinar um algoritmo para regressão com poucos dados é um pouco complicado pois pode não haver amostras o suficiente de uma determinada instância para o algoritmo captar padrões mais relevantes o que pode deixar as predições fracas.
Depois de algumas tentativas descobri que um jeito interessante de captar os melhores padrões é separar os dados pela média de um lado os que são maiores e de outro os que são menores e fazemos isso para cada coluna.
Depois disso medimos a variância do atributo Ação de cada subconjunto e selecionamos aquele com menor variância para ser o novo ramo. Depois refazemos o processo para cada subconjunto.
Existem muitas formas de se construir uma DT para regressões algumas mais simples e outras bem mais complexas optei por fazer dessa forma pela simplicidade com que o processo é feito.
Antes de começar vamos definir as técnicas que usaremos.
A media é representada pela seguinte fórmula:
Onde é o número de elemento do vetor, no nosso caso serão as colunas, e
é o valor do elemento.
Observação: desculpe pela forma como os parámetros das formulas estão representados no texto é que por algum motivo o Linkedin não aceita Latex mas coloquei as letras em negrito.
A variância é representada pela seguinte fórmula:
A variância para quem não sabe funciona como a média da diferença dos valores em relação a média.
Primeiro passo:
Calcula-se a média de todos os atributos\colunas menos a última pois essa é o alvo da predição.
media(Ipca) = 0.10
media(Ibovespa) = -0,12
média(Dolar) = 0.15
Depois disso separamos as instâncias. Vamos colocar as que são menores ou iguais a média de um lado e as que são maiores em outro. Fazemos isso para cada atributo.
Isso feito teremos o seguinte esquema.

Repare que já foi calculado a variáncia no preço de cada subconjunto formado por essa divisão.
Isso feito pegamos o atributo que melhor divide o Dataset em dois, repare que isso é uma forma de captar uma correlação entre o valor do atributo e o preço. A ideia é dividir em grupos cada vez mais semelhantes onde a variância no preço seja cada vez menor.
Escolhemos o Dolar pois um de seus subconjuntos tem a menor variância isso quer dizer que as instâncias são mais parecidas ali.

Repare que agora temos o nosso primeiro discriminante
Com isso feito repetimos o processo para cada ramo tiramos a média e separamos os maiores de um lado e os menores de outro fazemos isso para cada atributo e selecionamos aquele que melhor divide o conjunto.
Para fins didáticos usareis como folha o Node que tiver 3 ou menos amostras, pois se fazer o processo indefinidamente pode levar a árvore a overfitting. Apesar de não ser o melhor jeito é muito usado para evitar overfitting.
Se repetimos o processo teremos a seguinte estrutura:

Vamos repetir o processo mais uma vez agora para cada um dos 3 subconjuntos formados.
Repare que agora temos uma folha na árvore isso aconteceu pois a quantidade de amostras naquele ramo chegou em 3 então usei a média dos preços das ações que compunham essa amostra como output.
Vamos realizar mais uma iteração para ver como fica a estrutura.

Repare que ainda faltam 5 instâncias para usarmos para treino vamos repetir o processo. Depois de feito teremos a seguinte estrutura.

Você pode testar no conjunto de teste. Infelizmente ela não tem um desempenho tão bom pois usamos poucos dados para treino mesmo assim o resultado é interessante.

O Erro absoluto médio fica em torno de 0.4
Confesso ser muito bom apesar do método usado e da quantidade de dados.
Então é isso esse foi o post de hoje.
Como sempre qualquer dica, critica ou erro encontrado no post não exite em deixar nos comentários ate a próxima e bons estudos.
Para mais posts sobre machine learning acesse: O estudante independente