Para quem esta interessado em Machine learning assim como eu já deve ter ficado claro que a boa e velha abordagem Top-down muito comum no universo de TI não funciona muito bem. Isso acontece devido ao fato de que ML uni de forma muito sutil a teoria com a prática.
Nos meus estudos ate agora percebi que essa área exige uma alta capacidade de assimilar conceitos complexos, por mais que usemos os algoritmos na forma de “caixa preta” na pratica, mas mesmo assim é necessário um domínio da matemática e um profundo entendimento da linguagem de programação que será utilizada. Pensando nisso resolvi trabalhar alguns algoritmos de forma conceitual, teórica e prática.
Atualmente lido com três tipos de algoritmos: Perceptron, Decision tree e k-nearest neighbors apesar de simples tem muito a nos ensinar. E temos que levar em conta também os conceitos complementares necessários como: medir os erros e vieses saber explorar a linguagem de programação e claro a matemática por traz de cada algoritmo isso nos permite combiná-los de forma mais eficiente, porem leva tempo.
Devido a isso aconselho a focar em poucos algoritmos e procurar aplicá-los ou estudá-los mais depende do seu fim, acredito que é melhor saber usar muito bem poucas técnicas do que se atrapalhar com uma tonelada de coisa nova.
Primeiro contato com o algoritmo.
Decision tree talvez seja um dos algoritmos mais básicos de machine learning e ao mesmo tempo consiga lidar com um grande gama de problemas, por isso vamos nesse artigo analisá-lo de maneira conceitual.
Quando falamos em Decision tree fica claro que lidaremos com decisões essas por sua vez serão baseadas nas Características ou atributos da instância ou conjunto de instâncias em questão, para facilitar nosso estudo vamos partir de um exemplo simplificado, esse exemplo foi tirado do livro A curse in Machine learning eu apenas o adaptei para ficar mais prático e facilitar o aprendizado de quem nunca viu esse algoritmo.
Antes de tudo vamos definir o Conjunto de treino que será usado.
Ele consiste de uma simples pesquisa para saber se alguém gosta ou não de um curso, se você olhar para as colunas da tabela da esquerda para direita e usarmos a primeira instância como exemplo teríamos o seguinte:
-Você achou o curso fácil?
Sim.
-O curso é sobre IA?
Sim.
-Era um curso de verão?
Não.
-Já vez algum curso de verão antes?
Sim.
-Era na parte da manha?
Não
Gostol do curso?
Sim
Para deixarmos o conjunto mais fácil de processar futuramente, classificamos "Gostou" igual a 1 e "Não gostou” igual a 0.
Feito isso temos uma tabela igual a que se segue abaixo.
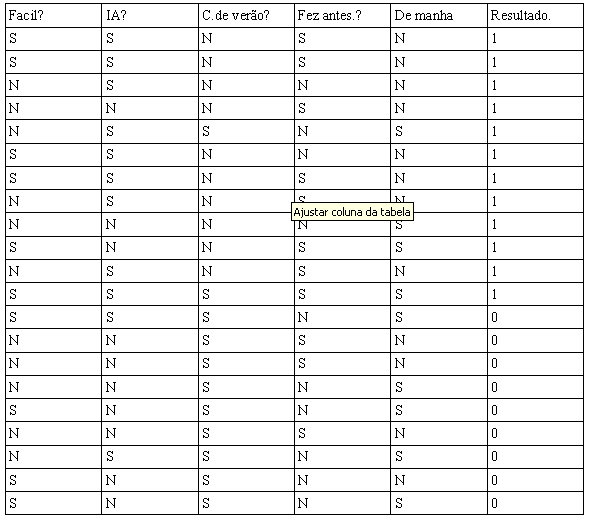
Quando se trata de Decision trees temos várias possibilidades para construí-las, por exemplo só nessa tabela simples acima podemos fazer milhares delas. porem nossa missão principal é fazer aquela que seja o mais otimizada possível, é claro que seria muito trabalho fazermos isso agora, porém podemos utilizar um histograma simples para modelarmos essa árvore em particular.
Vamos a principio separar nossos dados por respostas, por exemplo na primeira coluna quando perguntamos se um curso é fácil: iremos separar aqueles que responderam SIM e calcular quantos por cento deles gostaram ou não do curso, depois iremos contar quantos responderam NÃO e calcular quantos porcentos gostaram ou não do curso.
Fica assim:
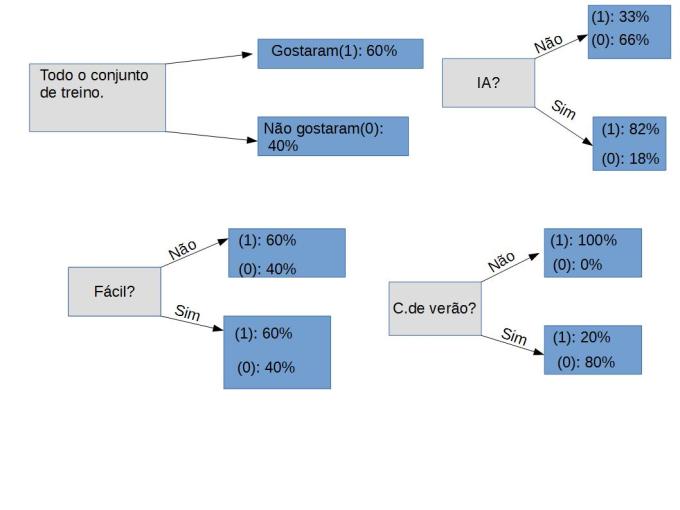
Mas se olharmos para a pergunta C.de verão? vemos que quando respondem não 100% gostaram do curso, logo podemos usar esse atributo para ser o primeiro Node ou a Raiz de nossa arvore, pois se alguém responde não é garantido que ela gostou do curso, caso responda sim em 80% dos casos ela não gostou do curso.
Pois bem a estrutura inicial fica assim:
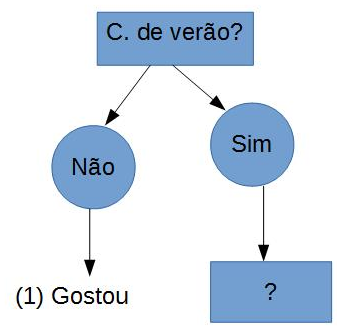
Então agora temos a primeira pergunta para nossa árvore, isso que dizer que todos os indivíduos do conjunto que responderam NÃO a C.de verão? Gostaram do curso. Porem agora temos que decidir como proceder caso a pessoa responda sim a essa pergunta.
Vamos apelar para recursão!. Usaremos agora apenas os casos em que responderam SIM para C.de verão? e fazer o mesmo procedimento.
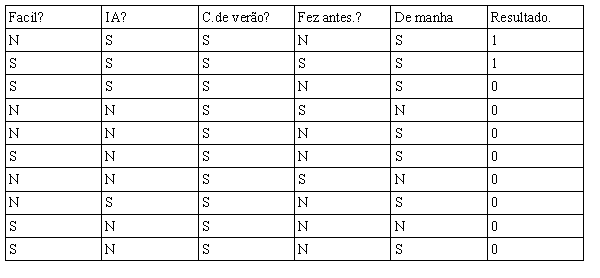
Na tabela acima temos apenas o conjunto de objetos em que foi respondido sim para C.de verão?vamos fazer os histogramas e ver qual próxima característica podemos usar para nos decidir.
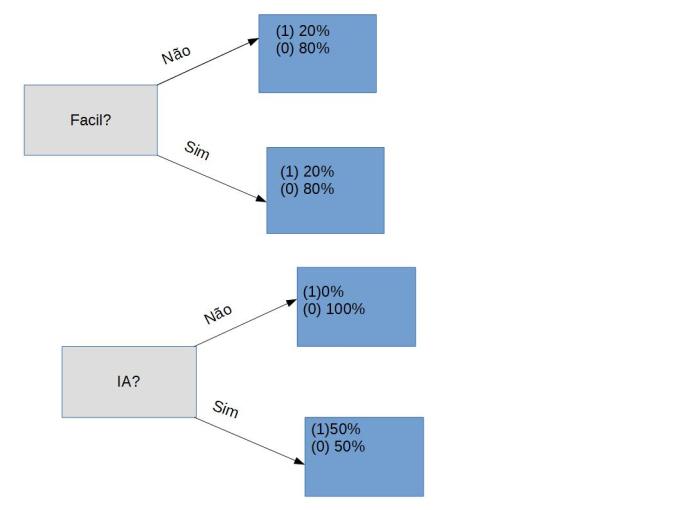
Fica claro que a resposta a pergunta Fácil? não é ideal pois tanto para NÃO quanto para SIM os conjuntos ainda são heterogêneos, mas quando se trata da pergunta IA?, os que responderam NÃO a essa pergunta todos não gostaram do curso logo podemos utilizar esse atributo para ser o próximo Node da arvore.
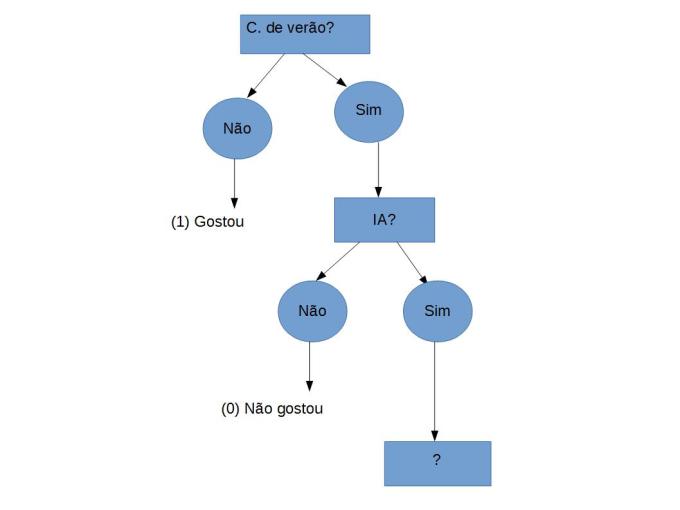
Mas ainda temos que fazer mais Nodes pois quando eles respondem sim para C. De verão? E sim para IA? Ainda não podemos dizer do que se trata então vamos repetir o mesmo procedimento e ver o que acontece.
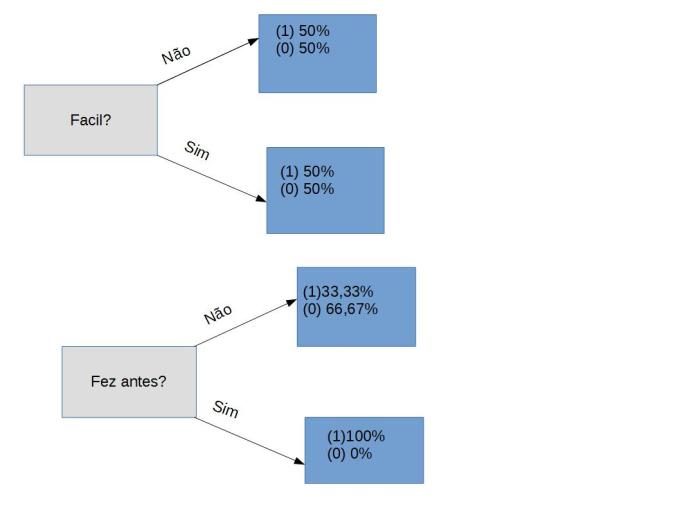
Achamos outro atributo que nos permite tomar uma decisão segura, quando perguntados Fez antes? Todos aqueles que responderam SIM gostaram do curso.
Logo podemos usar esse atributo para o próximo Node, mas antes disso repare como que esse algoritmo vem reduzindo nossos objetos a um conjunto onde os elementos se parecem entre si, isso é o principio da generalização pois identificamos novos objetos a partir das características que esses tem em comum com objetos já vistos antes por nos.
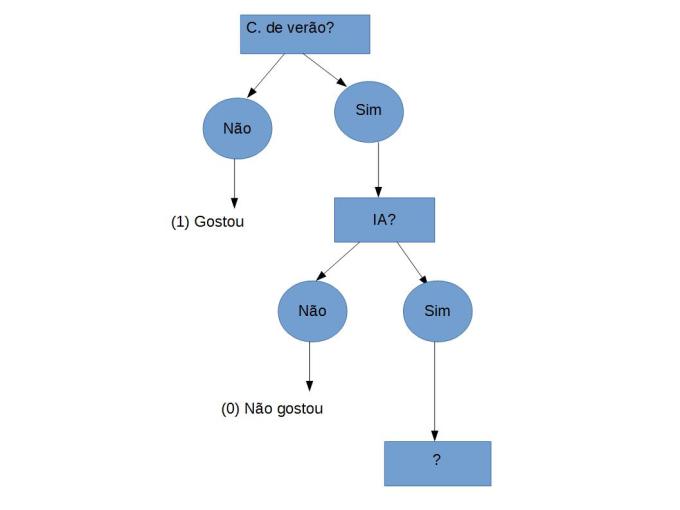
Agora estamos quase lá, porem ainda temos um conjunto sem classificar, por respeito a você leitor que já deve estar ficando chateado com tanta recursão irei pular para a versão final da arvore e para sua surpresa não poderemos fazer com que ela consiga classificar todo o conjunto por mais que usemos todas os atributos.
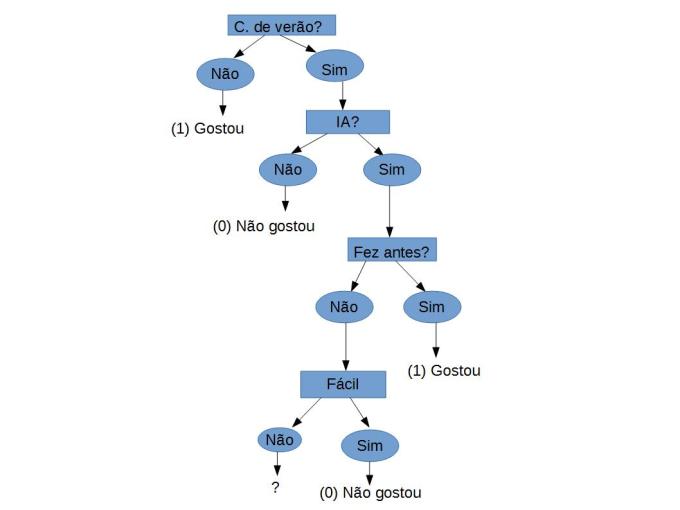
No final usamos todos os atributos que temos a disposição porem não deu para construir um uma arvore completa.
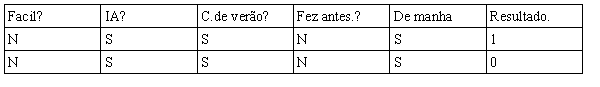
Repare que são instâncias idênticas porem pertencem a classes diferentes, não fique chateado o intuito era realmente que isso acontece-se pois em problemas de aprendizados é muito comum acontecer de não termos todas as atributos necessários para classificarmos um conjunto de dados.
Alias esse é um tema de estrema importância em Machine learning como um todo, mas para frente veremos que existe métodos mesmo que paliativos para lidar com esse tipo de situação.
Essa foi apenas uma demonstração simples de uma Decision tree binária, em exemplos mais práticos não é muito apropriado usar um simples histograma para decidir qual atributo selecionar para tomada de decisão, isso alias é algo importante quando lidamos com DT pois se trata do Score ou Ref que é o que vamos usar para tomar a decisão, um dos métodos mais usados é o information gain que se utiliza da entropia do conjunto para decidir qual o melhor node.
Vimos também que se a árvore tiver muitos nodes ela fica muito limitada na hora de classificar novos exemplos isso é overfiting caso ela fique muito rasa também é ruim pois pode não ter achado atributos o suficiente para tomar uma decisão satisfatória o que é chamado underfiting eu tratei um pouco disso em outros posts.
Apresentei aqui uma visão extremamente conceitual e simplificada do algoritmo, mas para você que se interessou vale a pena se aprofundar nesse algoritmo e aprender a aplicá-lo.
Ate o próximo post!