Para você que já vem estudando Machine Learning já deve ter se deparado com a seguinte situação. Seu algoritmo depois de treinado fazer maravilhas no conjunto de treino mas quando aplicado ao conjunto de teste ter um erro terrível. Ou o contrário disso! ter um desempenho ruim no conjunto de treino e acertar de maneira ate decente no conjunto de teste, caso ainda não tenha passado por isso é bom saber o que significa, pois a probabilidade de acontecer com você no futuro é bem alta.
Primeiramente vamos definir cada um dos três termos apresentados no título e depois analisar o comportamento de dois algoritmos simples e identificar o que é o Bias de um algoritmo e quando estamos diante de um caso de Underfinting ou overfiting.
Bias
O Bias que pode ser traduzido como o viés não é algo muito fácil de definir, para se ter uma ideia existem ate discussões filosóficas e torno do assunto, mas quero demonstrar de maneira prática do que se trata.
O exemplo abaixo foi inspirado no do livro A curse in machine learning.
De uma olhada na imagem abaixo.
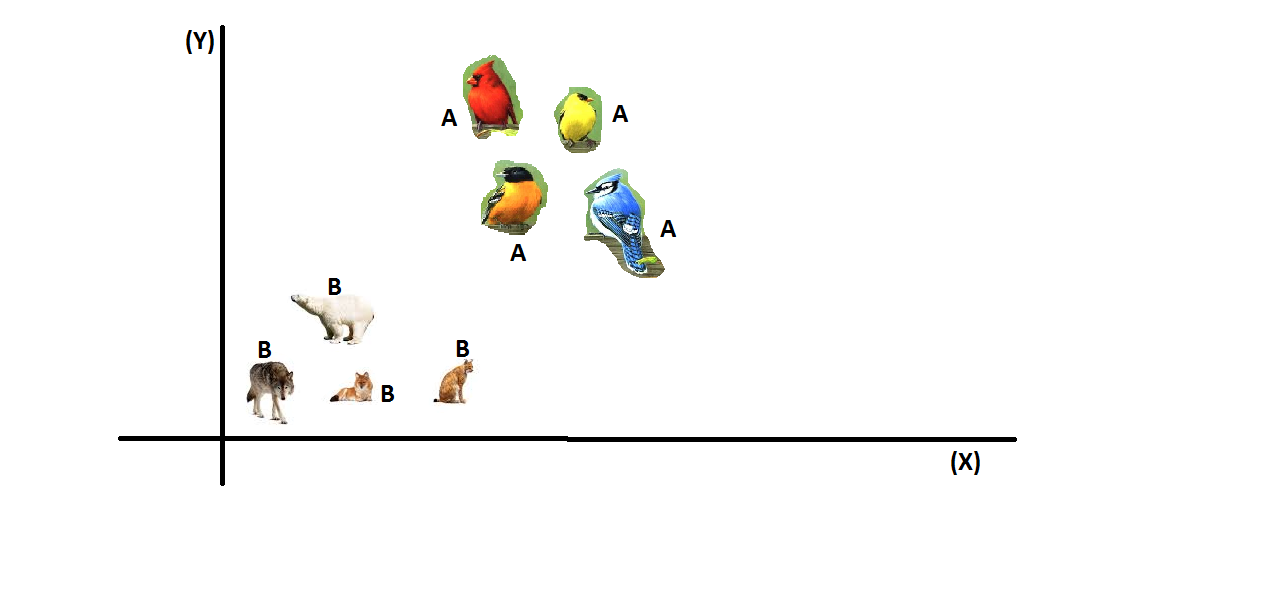
Agora use o que você aprendeu para classificar as figuras a seguir.

Alguns de vocês, eu arrisco dizer a grande maioria, ira classificar como ABABB enquanto outros irão classificar como ABBBA, pode parecer um pouco estranho mas isso acontece devido ao Bias indutivo(Inductive bias.) que cada um teve para tomar sua decisão e aprender com a primeira imagem.
Pois nesse caso temos no mínimo 2 jeitos de aprender o primeiro seria a classificação entre animais voadores e terrestres enquanto o segundo seria entre animais mamíferos e aves.
No exemplo acima caso a tarefa aprendida fosse separar entre mamíferos e aves o atributo mais relevante iria ser as penas com certeza.
Caso fosse separado entre voadores e terrestres o atributo mais importante iria ser as asas pois assim não deixaria o morcego passar direto.
Quando pensamos em algoritmos já é um pouco mais complicado definir um Bias pois cada algoritmo tende a ter comportamentos bem diferentes.
Mas por hora podemos definir Bias como o objetivo a ser aprendido aquilo que nos ira fazer tomar a decisão certa.
Em contraste com o Bias temos a variância, quando um algoritmo tem uma variância muito alta ele se torna sujeito a levar em conta ruídos ou dados específicos demais.
Começa a levar em conta características que não são importantes para a tarefa como a cor das penas por exemplo.
O ideal é ter um algoritmo equilibrado que não tenha um Bias muito elevado pois isso pode fazer com que ele não tenha a complexidade necessária para classificar as instâncias corretamente Mas que também não tenha uma variância muito alta para não considerar ruídos e dados aleatórios.
Algoritmos com alto bias tendem a fazer maiores conclusões sobre um conjunto de dados a partir de poucos atributos, as funções que mapeiam o conjunto são menos complexas tendem a ter uma maior taxa de erro no conjunto de teste.
Algoritmos com alta variância tendem a usar mais atributos para criar suas funções, são mais complexos pois aprendem muitas particularidades do conjunto de treino tendem a ter uma taxa erro menor no conjunto de treino.
Underfiting e overfiting
Como vimos acima fica claro que nosso algoritmo não pode generalizar demais porém não pode ser especifico demais o que precisamos é de um algoritmo equilibrado.
Existe dois jargões usados em ML que resume bem cada situação vamos falar deles.
Underfiting: Quando você treina seu algoritmo e testa ele no próprio conjunto de treino e percebe que ele ainda tem uma tacha de erro considerável. Então testa ele no conjunto de teste e percebe que a taxa de erro é semelhante mas ainda alta.
Isso quer dizer que estamos diante de um caso de Underfiting o algoritmo tem um alto bias e ainda podemos melhorar sua classificação, para isso deveremos mexer em alguns parâmetros do algoritmo.
Claro que em nem todos os casos ira ocorrer dessa forma depende da natureza do algoritmo.
Overfitting: Agora você treinou seu algoritmo e depois disso resolveu aplicá-lo em seu conjunto de treino e fica feliz quando percebe que ele teve uma taxa de erro de 0,035% por exemplo. Mas quando aplica no conjunto de teste percebe que ele tem um desempenho horrível.
Estamos diante de um caso de Overfitng, o Algoritmo tem baixo Bias não consegue generalizar muito bem, Isso acontece pois tem mais complexidade do que o necessário, considera atributos que não deveria por exemplo.
Nesse caso devemos deixar o algoritmo mais livre para conseguir generalizar melhor.
É importante lembrar que uma alta taxa de acerto no conjunto de treino não diz necessariamente overfitting
Vamos a dois casos práticos.
Para quem já vem estudando Machine Learning a um tempo já deve ter passado por esses dois algoritmos o KNN e Decision tree.
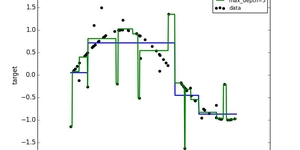
K-nearestneighboars: Esse algoritmo se utiliza de propriedades geométricas para tomar suas decisões. Ele usa o conjunto de treino toda vez que precisa classificar uma nova instância. Para fazer isso ele calcula a distância do vetor em relação a todos os outros vetores, depois ele classifica aquele vetor como sendo da classe dos K vetores mais próximos.
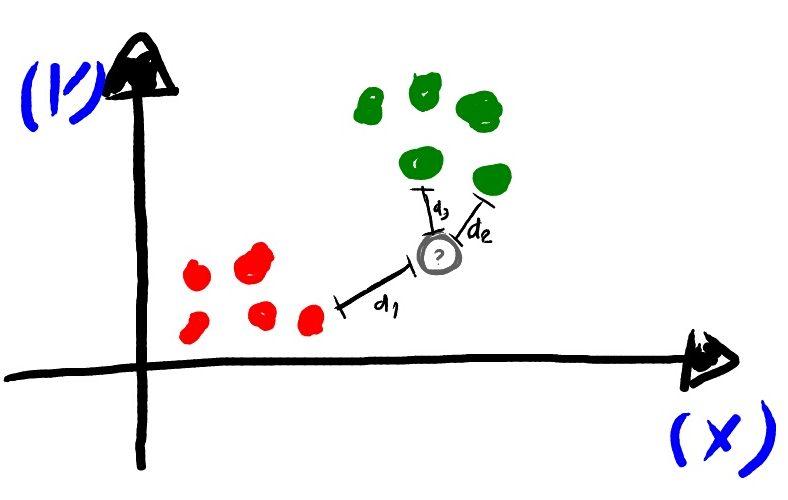
Como você pode ver na imagem acima ele mede a distância entre o vetor em relação aos seus vizinhos mais próximos(Nesse caso 3.) e logo em seguida o classifica como sendo da mesma classe dos dois vizinhos mais próximos, no caso um ponto verde.
Olhando dessa forma podemos perceber que o parâmetro que ira alterar o Bias de nosso algoritmo é o próprio K caso coloquemos ele para calcular a distância entre os 99 vizinhos mais próximos pode haver uma alteração na classificação.
Observe o gráfico abaixo:
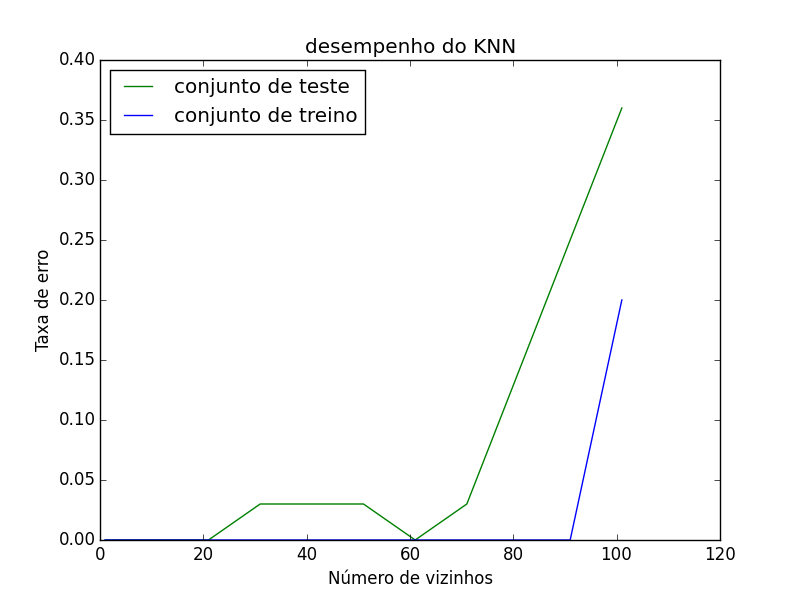
Devido a natureza do KNN quando aumentamos o número de vizinhos a taxa de erro é aumentada tanto no conjunto de treino quanto no de teste, observe que a taxa almenta no conjunto de teste há uma velocidade menor.
Isso acontece pois ele usa o próprio conjunto de treino como parte do algoritmo, mas fica claro que quanto mais vizinhos colocamos mais propenso a overfitting ele se torna. Porem quando temos menos vizinhos a taxa de erro nos dois conjuntos fica bem perto de zero isso acontece pois usei um conjunto de dados pequeno.
Caso queira saber mais sobre o algoritmo:
Classificação e regressão com K-nearest neighbors
K-nearest neighbors com scikit learn
K-nearest neighbors seu primeiro algoritmo de machine learning
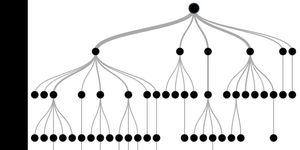
Decision tree:É um algoritmo determinístico. Ele procura no conjunto de dados uma maneira de separar as instâncias de acordo com o ganho de informação de seus atributos, isso faz com que o modelo lembre uma árvore.
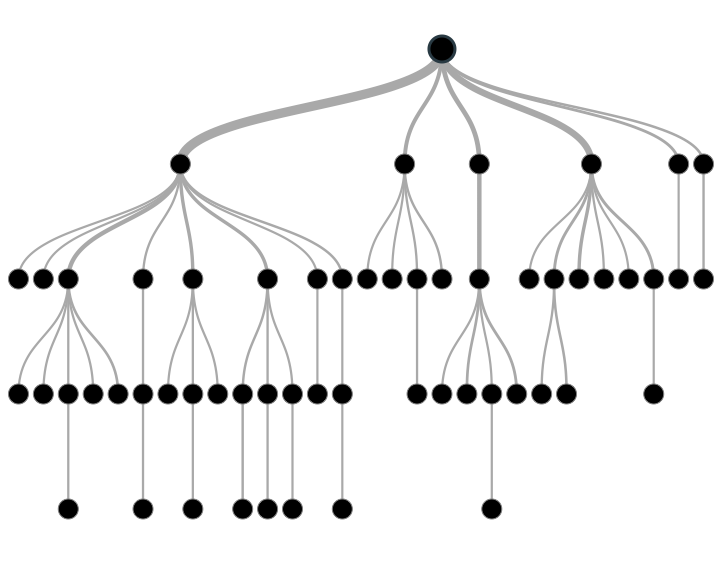
Nos chamamos de profundidade(depth) da árvore a quantidade de Nodes( as bolinhas) com ramos para outros nodes da árvore, quando não tem ramo é chamado folha que é por onde a instância sera classificada fica claro que um dos parâmetros que ira influenciar no Bias é sua profundidade e a quantidade de atributos que pode ser usada para medir a pureza do conjunto.
Medir o desempenho de uma DT não é tão simples quanto o do KNN mas vale a pena fazer algumas observações simplistas para entender o comportamento desse algoritmo.
Apliquei uma DT no conjunto de dados Titanic usei apenas três atributos Sexo,Idade e Classe da cabine.
Primeiro medi o desempenho de uma árvore usando apenas um atributo em diferentes profundidades.
Observe o gráfico abaixo:
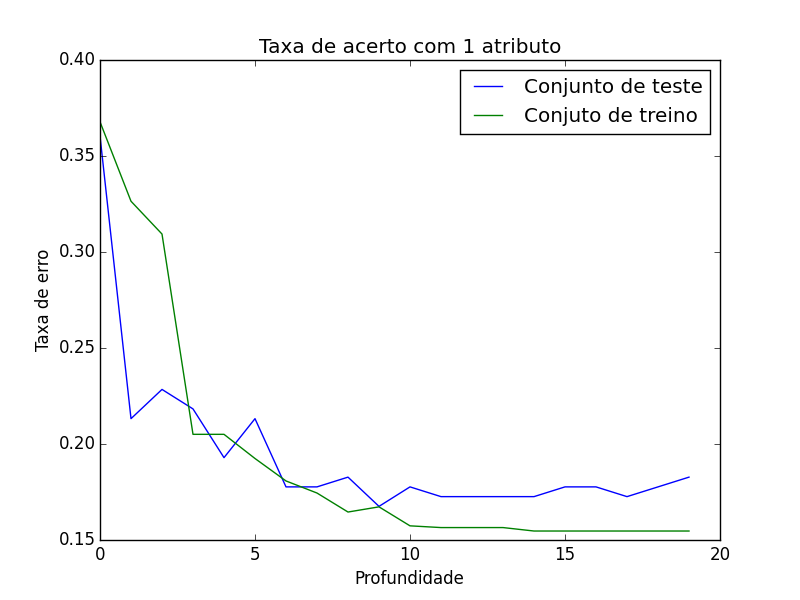
Repare na linha azul ela começa bem alta depois desse ate um limite e volta a aumentar isso acontece pois como só foi usado um atributo para treinar a árvore ela tem pouca informação para achar algum padrão quando a profundidade é pequena. Isso esta em um estado de Underfitting significa alto Bias.
Ao contrário quando a profundidade vai aumentando ela tende aumentar a variância e começa a generalizar menos isso é um estado de Overfitting.
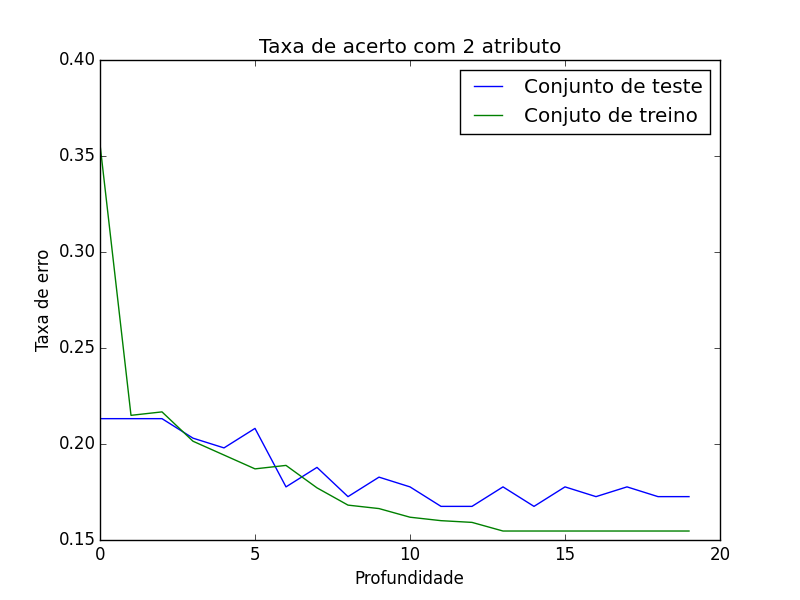
Com uma instância a mais a a taxa de erro no conjunto de treino começa a baixar bem mais cedo ela tende a entrar em estado de Overfiting mais rápido. Isso acontece pois como temos uma quantidade maior de atributos não é necessária uma árvore muito profunda para captar os padrões mais relevantes.
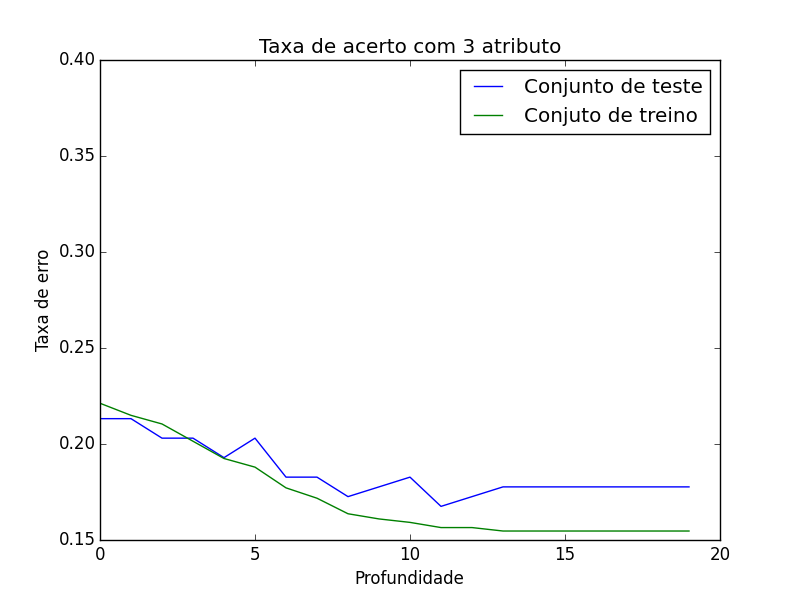
Agora com três atributos a taxa de erro no conjunto de treino fica baixa ainda mais rápido por mais que a taxa de erro tenda a baixar em uma profundidade maior é preciso ficar atento a maneira de como o conjunto esta organizado. sua distribuição probabilística por exemplo.
Então pessoas este foi o Post de hoje espero que tenha contribuído para seu aprendizado dessa área fascinante que é machine learning.
Qualquer dúvida, sugestão ou critica é sempre bem víndo e ate a próxima.
Resolva exercícios e atividades acadêmicas